Работа с контекстом в длинных промптах: теория, практика и рекомендации
 193
193
Почему контекст важен в промптах
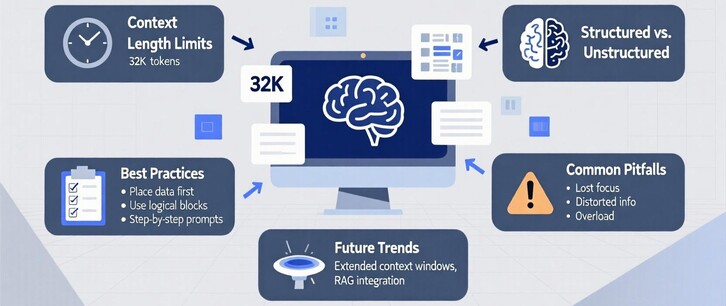
В LLM контекст играет ключевую роль в обеспечении точности и полезности ответов. Однако длинные промпты могут вызывать сложности: модели могут терять фокус, искажать информацию или не справляться с объемом данных. Это особенно актуально для задач анализа документов, сравнения данных или генерации сложных ответов.
Ограничения по длине контекста (до 32K токенов, Claude 1M токенов) заставляют пользователей искать эффективные способы работы с длинными промптами. Неправильное управление контекстом может снизить производительность, привести к потере ключевой информации или некорректным выводам. В этой статье рассмотрим, как оптимизировать работу с контекстом, используя теоретические подходы, практические примеры и лучшие практики.
Что такое длинный и структурированный контекст
Длинный контекст — информация, превышающая стандартные ограничения модели (например, 2048 токенов).
Структурированный контекст — упорядоченный способ представления данных, который помогает модели лучше понять задачу.
Почему это важно?
- Длинный контекст позволяет учитывать больше данных, но требует осторожности: слишком большой объем снижает точность ответа.
- Структурированный подход упрощает понимание задачи, снижает риск искажений и повышает вероятность корректного результата.
Практические техники: как управлять контекстом в длинных промптах
1. Размещайте данные вверху промпта
Техника:
Поместите основные данные (текст, таблицу, историю) в начало промпта. Это позволяет модели сразу получить доступ к ключевой информации.
Пример:
[Данные]
Конфиденциальный документ:
1. Условия контракта: 2023 год, срок 12 месяцев.
2. Стороны: Компания A и Компания B.
[Запрос]
Пожалуйста, извлеките основные условия контракта и сформулируйте их в виде списка.
Почему это работает?
Модель сначала видит данные, а затем получает инструкцию. Это снижает вероятность потери информации.
2. Структурируйте контекст: разбиение на логические части
Техника:
Разделите текст на короткие фрагменты, используйте заголовки или маркированные списки.
Пример:
[Контекст]
1. Введение:
- Цель: Анализ эффективности проекта.
- Дата: 2023-04-01.
2. Данные:
- Продуктивность: 85% (окт. 2022) → 92% (апр. 2023).
[Запрос]
Сравните продуктивность в октябре 2022 и апреле 2023.
Почему это работает?
Структура помогает модели быстрее находить нужную информацию.
3. Поэтапное предоставление контекста
Техника:
Разбейте сложную информацию на шаги. Это особенно полезно для анализа или последовательных действий.
Пример:
[Шаг 1]
Извлеките основные условия контракта из текста:
"Контракт на 12 месяцев, стороны: A и B, права на изменение условий."
[Шаг 2]
Сравните условия контракта с текущими правилами компании A.
Почему это работает?
Модель фокусируется на отдельной задаче, снижая риск ошибок.
Пошаговые инструкции: как создать эффективный промпт с контекстом
-
Определите цель:
Четко сформулируйте, что нужно получить от модели. Например: "Извлеките ключевые моменты из документа и сформулируйте их в виде списка". -
Поместите данные в начало:
Разместите текст, таблицы, историю в начале промпта. -
Структурируйте информацию:
Разделите текст на логические блоки, используйте заголовки или маркированные списки. -
Добавьте инструкции по обработке:
Укажите, как модель должна обрабатывать данные (например, "Сравните данные с правилами компании"). -
Укажите формат ответа:
Определите, как должен выглядеть результат (например, "Составьте список в формате JSON").
Пример:
[Шаг 1]
Извлеките основные условия контракта из текста:
"Контракт на 12 месяцев, стороны: A и B, права на изменение условий."
[Формат ответа]
Составьте список в формате JSON с ключами: "стороны", "срок", "права".
Советы и лучшие практики
| Стратегия | Описание |
|---|---|
| Ограничивайте объем контекста | Слишком большой объем снижает точность. Разбейте промпт на шаги. |
| Используйте структурированный подход | Упорядоченный текст упрощает понимание модели. |
| Проверяйте краткость и ясность | Удалите лишнюю информацию, оставьте только ключевые данные. |
| Учитывайте ограничения модели | Проверяйте документацию модели (например, YandexGPT-5 поддерживает до 32K токенов). |
Новейшие разработки в области работы с контекстом
1. Расширение контекстного окна
Модели, такие как Llama 3, поддерживают контекст до 100K токенов. Это открывает возможности для анализа больших объемов данных, но требует осторожности: слишком большой объем может снизить производительность.
2. Интеграция с RAG
Работа с контекстом в RAG позволяет использовать внешние данные (например, базы знаний) для улучшения ответов. Это особенно полезно для задач, где требуется точность (например, юридические или медицинские запросы).
Пример:
[Контекст]
1. Нормы законодательства: Закон №123 от 2020 года.
2. Кейсы: Кейс A: разрешение на изменение условий.
[Запрос]
Какие законы применяются к изменению условий контракта?
Рекомендации
Работа с контекстом в длинных промптах требует баланса между объемом информации и структурированностью. Следуя рекомендациям, вы можете значительно повысить точность и эффективность ответов.
Основные рекомендации:
1. Размещайте данные в начале промпта.
2. Используйте структурированный подход: разделение на логические блоки.
3. Разбивайте сложные задачи на этапы.
4. Уточняйте формат ответа.
5. Проверяйте ограничения модели.
С развитием моделей с более широким контекстным окном и интеграцией с RAGработа с длинными промптами станет еще более эффективной. Однако важно помнить: качество ответа зависит не только от объема контекста, но и от его структуры и ясности.
Авторизуйтесь, чтобы оставить комментарий.
Нет комментариев.
Тут может быть ваша реклама
Пишите info@aisferaic.ru
Похожие статьи


Self-Consistency – Самосогласованность: как повысить точность ответов LLM
 0,0
221
0,0
221

Рассуждение (Reasoning) в больших языковых моделях (LLM): теория и практика
0,0
177

Function Calling в AI: Как LLM взаимодействуют с внешними инструментами
0,0
232