Qwen3-Omni-Captioner: Аудио-анализ ИИ, кейсы и применение

 183
183
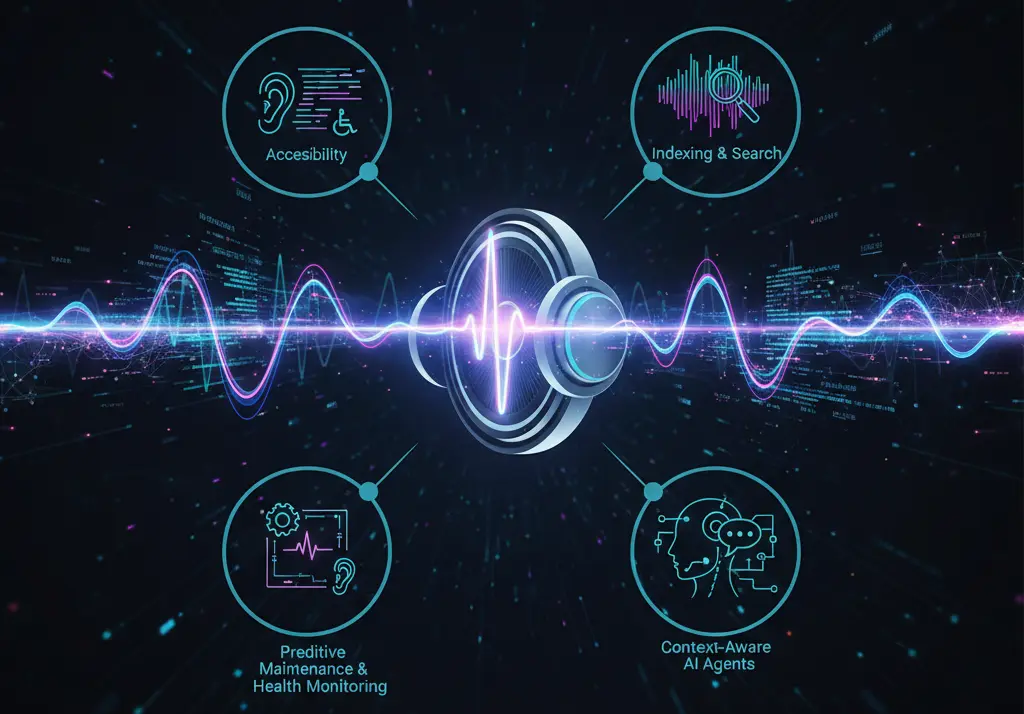
Недавний релиз от Alibaba Cloud специализированная мультимодальная модель Qwen3-Omni-30B-A3B-Captioner — знаменует собой прорыв, который выходит далеко за рамки традиционных систем распознавания речи (ASR). Если классические модели занимаются исключительно транскрибированием слов, то Qwen3-Omni-30B-A3B-Captioner способна детально описывать весь звуковой ландшафт вокруг, генерируя высококачественные и контекстуально обогащенные подписи (captions) для произвольных аудиовходов. Эта уникальная способность, выпущенная в рамках семейства Qwen3-Omni по открытой лицензии Apache 2.0, открывает двери для ряда критически важных и инновационных применений в самых разнообразных отраслях.
Пожалуй, наиболее гуманитарным и социально значимым применением этой технологии является устранение цифровых барьеров для людей с нарушениями слуха. Qwen3-Omni-30B-A3B-Captioner выступает в качестве цифровых "ушей", обеспечивая полный доступ к информации, которая ранее передавалась исключительно в звуковом формате.
Модель генерирует не просто субтитры для диалогов, но и контекстуальные аудио-описания неречевых звуков, которые являются критически важными для понимания контента и окружающей среды. Например, при просмотре фильма или подкаста субтитры обогащаются такими деталями, как "слышен громкий стук в дверь", "музыка становится драматичной и напряженной", "зрители аплодируют", или "взрывается смех толпы". Это позволяет неслышащим пользователям получить полное представление о сюжете, атмосфере и эмоциональном фоне, которые передаются звуковой дорожкой.
Более того, модель находит практическое применение в системах умного оповещения. Интегрированная в бытовые или общественные системы, она способна распознавать и классифицировать важные бытовые и тревожные звуки — от звонка в дверь и плача ребенка до сработавшей пожарной или охранной сигнализации. Преобразование этих звуков в мгновенные текстовые или визуальные уведомления становится жизненно важной функцией, обеспечивающей безопасность жилых пространств.
Глубокое индексирование, поиск и анализ контента в масштабе
Для работы с экспоненциально растущим объемом медиа-данных и в системах безопасности модель Qwen3-Omni-30B-A3B-Captioner становится мощнейшим инструментом аналитики и каталогизации, предоставляя многомерный подход к обработке аудиоинформации.
Традиционные методы поиска в медиа-архивах, подкастах или радиопередачах ограничивались поиском по произнесенным словам. Эта же модель позволяет совершить прорыв, обеспечивая глубокий поиск по звуковому ландшафту. Теперь можно проиндексировать огромные хранилища контента и находить записи, содержащие не только конкретные речевые фразы, но и конкретные звуковые события — например, "шум дождя", "пение птиц", "сильный ветер" или "движение транспорта". Это позволяет разработчикам контента, библиотекарям и исследователям находить необходимый материал с беспрецедентной точностью.
Студии и производители медиа-контента могут использовать модель для автоматической генерации подробных метаданных (например, описание настроения, жанра, типа звука), что упрощает управление активами.
Улучшение взаимодействия человека и компьютера
Наконец, модель играет ключевую роль в создании нового поколения контекстно-осведомленных ИИ-агентов и голосовых помощников.
Традиционные голосовые помощники часто терпят неудачу в шумной или сложной акустической среде. Qwen3-Omni-30B-A3B-Captioner решает эту проблему, обогащая команду пользователя контекстом окружающей среды. Если пользователь говорит команду "на фоне сильного шума улицы", "в окружении других голосов" или "при включенном радио", агент получает это описание вместе с транскрипцией. Благодаря этой дополнительной информации агент может принять более интеллектуальное и адаптивное решение: он может вежливо переспросить, говорить громче или проигнорировать команду, если она была подана слишком неясно. Эта возможность добавляет в ИИ-взаимодействие уровень человеческой интуиции, принципиально улучшая взаимодействие человека и компьютера (HCI), делая агентов более эффективными и "понятливыми" в реальных условиях.
Выпуск Qwen3-Omni-30B-A3B-Captioner — это не просто новый релиз; это фундаментальный шаг к созданию систем, которые воспринимают мир так же, как люди, объединяя слух и понимание. Специализация на подробном аудио-описании делает эту модель незаменимым инструментом для разработчиков, стремящихся к созданию более инклюзивных, безопасных и интеллектуальных приложений будущего, основанных на богатом контексте звуковой среды.
Авторизуйтесь, чтобы оставить комментарий.
Нет комментариев.
Тут может быть ваша реклама
Пишите info@aisferaic.ru
Похожие статьи


ucm: построение моделей мира с помощью временного позиционного кодирования
 0,0
3
0,0
3
Как AI ломает правила в IT: CTO EliseAI о новых требованиях к разработчикам
0,0
95