Что такое графовая база данных
 217
217
Мы живем в эпоху, когда данные больше не воспринимаются как изолированные записи в таблицах. Они всё чаще представляют собой сеть взаимосвязанных сущностей — пользователей, событий, транзакций, документов. Если в классических реляционных базах данных упор делается на хранение и обработку структурированной информации в таблицах, то современным задачам этого уже недостаточно. Особенно это заметно в эпоху искусственного интеллекта, где алгоритмы обучения требуют работы не только с данными, но и с контекстом их связей.
Графовые базы данных появились как ответ на этот вызов. Они позволяют хранить информацию так, как мы её воспринимаем в реальности: в виде объектов и связей между ними. Представьте себе социальную сеть. Пользователь не просто запись в таблице — он связан с друзьями, фотографиями, лайками и сообществами. Чтобы ответить на вопрос «кто из друзей моих друзей любит ту же музыку, что и я», реляционная база должна выполнить множество сложных объединений (JOIN), тогда как графовая база справляется с этим практически мгновенно.
Эта способность эффективно работать со связями делает графовые базы критически важными для искусственного интеллекта и анализа больших данных. Они обеспечивают основу для рекомендаций, поиска, анализа графов знаний, построения онтологий и reasoning в LLM. Сегодня такие базы всё чаще используются в задачах кибербезопасности, финансовой аналитики, биоинформатики и даже в логистике.
Таким образом, понимание того, как работают графовые базы данных, становится не просто любопытством, а важным навыком для специалистов в области AI и анализа данных. Эта статья поможет разобраться в концепции, архитектуре и практических сценариях их применения, а также на конкретных примерах показать, чем они отличаются от привычных реляционных систем.
Основы графовой модели: вершины и рёбра
В центре графовой базы данных лежит простая, но мощная идея: данные представляются в виде вершин и рёбер. Вершины описывают сущности, такие как человек, продукт или событие. Рёбра связывают вершины и задают тип отношений: «знает», «купил», «работает в», «принадлежит». При этом и вершины, и рёбра могут иметь набор свойств, которые уточняют детали.
Например, если рассматривать граф сотрудников компании, вершина «Анна» может содержать свойства: должность = «аналитик», отдел = «финансы». Рёбра могут связывать её с вершиной «Иван» через отношение «работает вместе» и с вершиной «Проект X» через отношение «участвует». Такой способ моделирования сразу делает очевидными скрытые связи — например, можно мгновенно найти сотрудников, участвующих в одних и тех же проектах.
Эта модель интуитивно понятна и повторяет естественный способ восприятия информации человеком. Она особенно полезна, когда количество связей между объектами превышает количество самих объектов, что часто встречается в социальных сетях, системах рекомендаций или анализе знаний.
Как графовые базы отличаются от реляционных
Реляционные базы данных (SQL) строятся на таблицах, где строки — это записи, а столбцы — атрибуты. Для описания связей приходится использовать внешние ключи и сложные операции объединений. Когда данные сильно взаимосвязаны, такие операции становятся дорогими и медленными.
Графовые базы работают иначе, поиск соседей вершины или обход сети выполняется напрямую, без вычислительных накладных расходов. В задачах вроде поиска кратчайшего пути, выявления сообществ или анализа связности графовые базы показывают существенное преимущество.
Простой пример: задача «найти всех друзей друзей пользователя». В SQL это приведет к многоуровневым JOIN-запросам, а в графовой базе это будет простая операция обхода на два уровня. Разница в производительности может быть большой.
Языки запросов: от SQL к Cypher и Gremlin
Для работы с графовыми базами используются специализированные языки. Наиболее известные — Cypher (Neo4j), Gremlin (Apache TinkerPop) и SPARQL (в основном для RDF-графов).
Cypher строится на идее «рисования» графа в запросе. Например, чтобы найти всех друзей пользователя с именем «Анна», можно написать:
MATCH (a:Person {name: "Анна"})-[:FRIEND]->(friend)
RETURN friend
Этот запрос буквально читается как «найди вершину Person с именем Анна, перейди по ребру FRIEND и верни всех связанных друзей».
Gremlin, в отличие от Cypher, использует более функциональный стиль и подходит для сложных вычислений на графах. А SPARQL ориентирован на семантические графы и используется в области знаний, где важна совместимость с онтологиями и стандартами.
Примеры практического применения
Социальные сети
Социальные сети используют графовые базы, чтобы находить «людей, которых вы можете знать», предлагать группы и сообщества, а также рекомендовать контент. Сложные алгоритмы рекомендации строятся на многослойных графах связей.
Финансовый сектор
Банки применяют графы для выявления подозрительных транзакций. Например, можно построить граф, где вершины — это счета, а рёбра — переводы. Обнаружив аномальные цепочки переводов, система выявляет мошеннические схемы быстрее, чем при классическом анализе таблиц.
Биология и медицина
Графы помогают строить модели взаимодействия генов, белков и лекарственных средств. Это ускоряет поиск новых препаратов и понимание механизмов заболеваний.
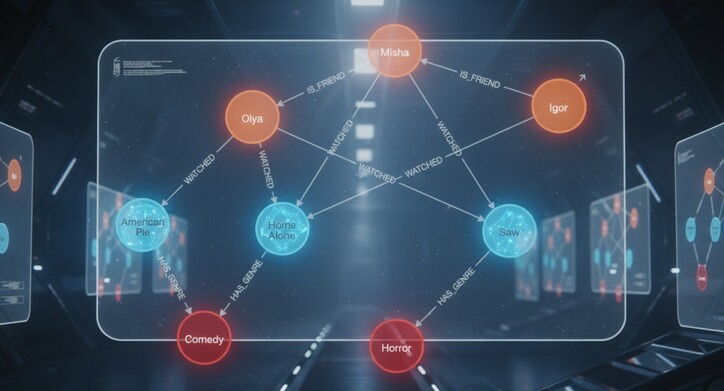
Пример: граф рекомендаций фильмов
Допустим, у нас есть база фильмов и пользователей. Вершины — это «Пользователь» и «Фильм». Рёбра связывают пользователя с фильмами, которые он смотрел или оценивал.
Если пользователь А посмотрел «Матрицу» и «Начало», а пользователь Б посмотрел «Начало» и «Интерстеллар», то граф покажет связь: А и Б похожи по вкусам. Следовательно, можно порекомендовать пользователю А фильм «Интерстеллар».
Такой механизм рекомендаций лежит в основе Netflix и других стриминговых сервисов. В графовой модели он реализуется через простые обходы и поиск похожих подграфов.
Интеграция графовых баз с AI
Графовые базы данных играют важную роль в развитии AI. Они используются для построения knowledge graphs — баз знаний, где хранится структурированная информация о сущностях и их отношениях. Эти графы помогают языковым моделям лучше понимать контекст и рассуждать над фактами.
Например, если модель должна ответить на вопрос «Какие фильмы снял Кристофер Нолан после 2010 года», то наличие графа знаний позволяет ей не только помнить факты, но и строить логическую цепочку. Граф становится дополнительным «мозгом», который расширяет возможности AI и снижает риск галлюцинаций.
Графовые базы данных — это не просто ещё один инструмент хранения информации. Это новая парадигма работы с данными, которая особенно актуальна в эпоху искусственного интеллекта. Когда мы имеем дело с огромными, взаимосвязанными массивами информации, графы становятся естественным выбором.
В ближайшие годы их применение будет только расти. От финансов до медицины, от кибербезопасности до генеративных моделей — графовые базы помогут находить смыслы там, где таблицы уже бессильны.
Если вы работаете в области AI, дата-инжиниринга или просто хотите понимать современные технологии, изучение графовых баз стоит поставить в свой список приоритетов. Попробуйте начать с Neo4j, построить небольшой граф своей социальной сети или фильмотеки, поиграть с запросами в Cypher. Это даст вам не только практическое понимание, но и новое видение того, как устроен мир данных вокруг нас.
Авторизуйтесь, чтобы оставить комментарий.
Нет комментариев.
Тут может быть ваша реклама
Пишите info@aisferaic.ru
Похожие статьи

Как AI ломает правила в IT: CTO EliseAI о новых требованиях к разработчикам
 0,0
94
0,0
94